Répertoire GitHub:
- GitHub
 : https://github.com/alegarn/S4J2-THP2-Pandas-Basics
: https://github.com/alegarn/S4J2-THP2-Pandas-Basics
Language:
 Python
Python
Librairies:
- Pandas
- MySQL Connector (Musées)
- SQLite connector (Panama Paper)
Type de projet:
- Petits projets
- Data Analyse
La librairie Pandas
Pandas est une librairie Python très utilisée en Data Analyse car elle comporte les outils nécessaires à une analyse de donnée (effectuer un chargement, un nettoyage, une transformation et une analyse).
Toute donnée est transformée en « Dataframe », bloc de base avec la librairie Pandas. Les Dataframes sont des tableaux pouvant accueillir des millions de lignes et de colonnes… si vous avez assez de mémoire RAM.
Une analyse basique
Le but de cet exercice est de manipuler Pandas directement en effectuant une analyse. Ici peu de nettoyage, et des commandes de base.
Et voici un intitulé comportant les questions.
Répondre aux questions posées par ton manager
Ton manager t’a donné une liste de questions pour te rendre la tâche plus concrète. Il t’a demandé de répondre à ces questions dans un premier temps en laissant apparentes tes requêtes sur le Notebook.
- Combien y-a-t-il de musées en France métropolitaine ?
- Dans quelle(s) ville(s) y-a-t-il de plus de musées ?
- Quel est le nombre moyen de musées par ville ?
- Quel est le nombre médian de musées par ville ?
- Comment sont répartis les musées par type (en pourcentage) ?
- Combien y-a-t-il de musées dont le nom commence par « Château » ?
- Pour combien de musées dispose-t-on de l’adresse du site web ?
- Quel département français possède le plus de musées sur son territoire ?
- Quel département français possède le moins de musées sur son territoire ?
- Combien de musées ont « Napoléon » dans leur nom ?
Charger et nettoyer les données
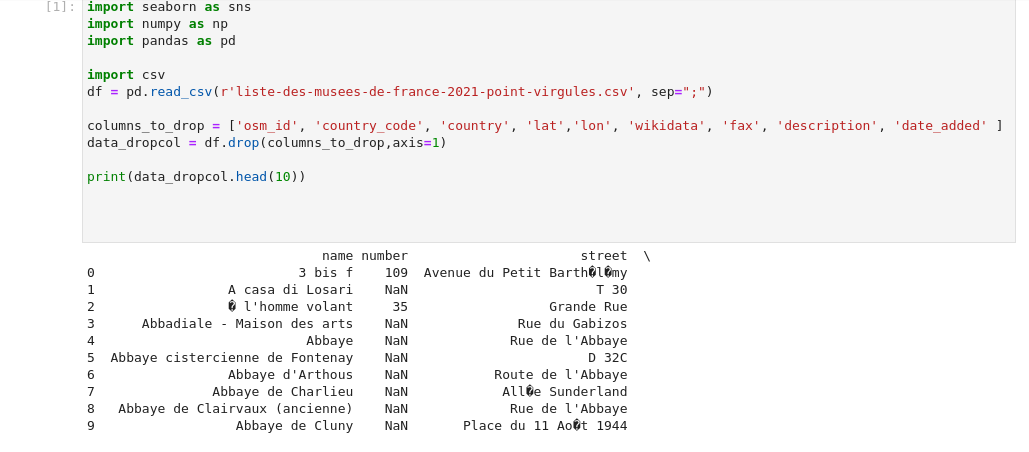
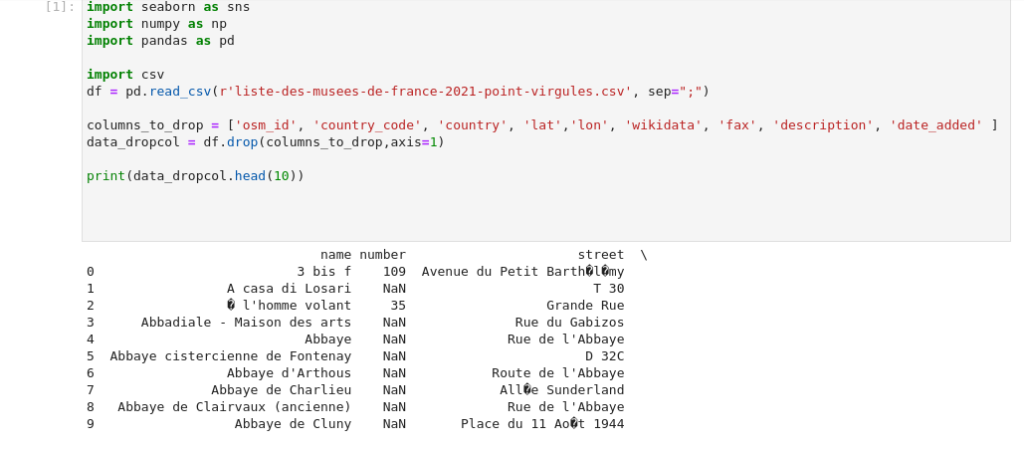
Toute analyse commence par importer les librairies, chargement, le nettoyage de donnée, cette fois ci très succint: enlever les colonnes en trop.
import seaborn as sns
import numpy as np
import pandas as pd
import csv
df = pd.read_csv(r'liste-des-musees-de-france-2021-point-virgules.csv', sep=";")
columns_to_drop = ['osm_id', 'country_code', 'country', 'lat','lon', 'wikidata', 'fax', 'description', 'date_added' ]
data_dropcol = df.drop(columns_to_drop,axis=1)
print(data_dropcol.head(10))Manipuler les Dataframes
- Combien y-a-t-il de musées en France métropolitaine ?
index = data_dropcol.index
number_of_rows = len(index)
total_museum = number_of_rows
museum_number_template = """Il y a au total {} musées en France."""
museum_number_message = museum_number_template.format(total_museum)
print(museum_number_message)Il y a au total 3784 musées en France.
- Dans quelle(s) ville(s) y-a-t-il de plus de musées ?
data_cities_all_col = pd.DataFrame(data_dropcol, columns= ['name','city'])
city_museum_number_template = """Il y a au total {} musées en France."""
museum_number_each_city = data_cities_all_col.pivot_table( columns=['city'], aggfunc='size').sort_values
number = data_cities_all_col['city'].str.split(' ').str[0:3].value_counts()
number_top_10_text = """Le top 10 'villes avec le plus de musées en France:
{} """
number_top_10_message = number_top_10_text.format(number[0:11])
print (number_top_10_message)
Le top 10 'villes avec le plus de musées en France: [Paris] 175 [Lyon] 33 [Marseille] 28 [Grenoble] 22 [Bordeaux] 20 [Toulouse] 20 [Nice] 16 [Strasbourg] 16 [Rouen] 15 [Lille] 15 [Reims] 13 Name: city, dtype: int64
- Quel est le nombre moyen de musées par ville ?
per_city_number_museum_mean = """Il y a en moyenne {} musées par ville."""
museum_number_each_city_mean = data_cities_all_col.pivot_table( columns=['city'], aggfunc='size').mean(axis=0)
museum_mean_message = per_city_number_museum_mean.format(museum_number_each_city_mean)
print(museum_mean_message)Il y a en moyenne 1.647930283224401 musées par ville.
- Quel est le nombre médian de musées par ville ?
per_city_number_museum_median = """Nombre médian de musées par ville: {}"""
museum_number_each_city_median = data_cities_all_col.pivot_table( columns=['city'], aggfunc='size').median(axis=0)
museum_median_message = per_city_number_museum_median.format(museum_number_each_city_median)
print(museum_median_message)Nombre médian de musées par ville: 1.0
- Comment sont répartis les musées par type (en pourcentage) ?
data_tags = pd.DataFrame(data_dropcol, columns = ['name','tags'])
museum_number_each_tag = data_tags.pivot_table(columns=['tags'], aggfunc='size')
museum_number_each_tag_percent = pd.DataFrame(museum_number_each_tag, columns=['size'])
museum_number_each_tag_percent['percent'] = (museum_number_each_tag_percent['size'] / museum_number_each_tag_percent['size'].sum()) * 100
sample = museum_number_each_tag_percent.loc[museum_number_each_tag_percent["percent"]>5]
museum_tag_message_string = """Voici la répartition (> 5%) des types de musée:
{}"""
museum_tag_message = museum_tag_message_string.format(sample)
print(museum_tag_message)Voici la répartition (> 5%) des types de musée:
size percent
tags
osm:museum 2175 57.509254
osm:museum;type:ecomusee 387 10.232681
osm:museum;type:musee technique et industriel 194 5.129561
- Combien y-a-t-il de musées dont le nom commence par « Château » ?
name_castle_sentence = """Il y a un nombre de 'Château' musée de {} ."""
sample
name_castle = pd.DataFrame(data_dropcol, columns= ['name']).add_prefix('name_')
name_castle['name'] = data_dropcol['name'].str.replace('�', "â")
new = name_castle['name'].str.split(' ').str[0].value_counts()
print(name_castle_sentence.format(new['Château']))Il y a un nombre de 'Château' musée de 48 .
- Pour combien de musées dispose-t-on de l’adresse du site web ?
with_website_template = """Il y a {} musées possédant un site internet."""
frame_internet = data_dropcol.pivot_table(index="website", values="name", aggfunc=np.count_nonzero)
with_website = with_website_template.format(frame_internet.sum(axis=0)['name'])
print(with_website)Il y a 1636 musées possédant un site internet.
- Quel département français possède le plus de musées sur son territoire ?
city_zipcode_text = """Le département français ayant le plus de musées est le {} avec {} musées."""
city_zipcode = pd.DataFrame(data_dropcol, columns= ['name', 'postal_code'])
city_zipcode['department'] = city_zipcode['postal_code'].astype(str).str[:2]
museum_each_dep = city_zipcode.pivot_table(columns=['department'], aggfunc='size').add_prefix('zip_')
city_zipcode_message_zip = city_zipcode_text.format(museum_each_dep.loc[museum_each_dep == museum_each_dep.max()].to_string()[15:18], museum_each_dep.loc[museum_each_dep == museum_each_dep.max()][0])
print(city_zipcode_message_zip)Le département français ayant le plus de musées est le 75 avec 180 musées.
- Quel département français possède le moins de musées sur son territoire ?
city_zipcode_text_lower = """Le département français ayant le moins de musées est le {} avec {} musées."""
dep_zip_less = museum_each_dep.loc[museum_each_dep == museum_each_dep.min()].to_string()
dep_zip_total_min = museum_each_dep.loc[museum_each_dep == museum_each_dep.min()][0]
city_zipcode_full_message = city_zipcode_text_lower.format(dep_zip_less[15:18], dep_zip_total_min)
print(city_zipcode_full_message)Le département français ayant le moins de musées est le 98 avec 8 musées.
Déduction: Les outre-mer.
- Combien de musées ont « Napoléon » dans leur nom ?
number_museum_emperor_template = """Il y a {} musées 'Napoléon'."""
search_name = pd.DataFrame(data_dropcol, columns= ['name'])
search_name['name'] = data_dropcol['name'].str.replace('�', "é")
contain_values = search_name[search_name['name'].str.contains('Napoléon')].count()
number_museum_emperor_text = number_museum_emperor_template.format(contain_values.to_string())
print(number_museum_emperor_text)Il y a name 4 musées 'Napoléon'.
Voilà, c’était une des premières utilisations de Pandas! (la 1ère…)
Le Bonus
Du SQL sur les Panama Papers: https://github.com/alegarn/S4J4-THP2-Basic-SQL
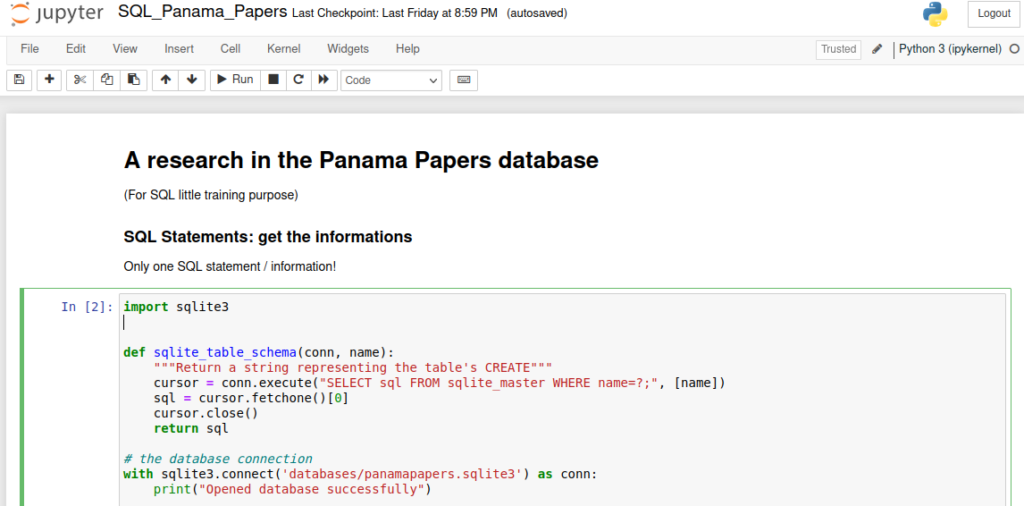
L’exploration de la base de donnée (retourner chaque table, leur relations et toutes les colonnes).
import sqlite3
def sqlite_table_schema(conn, name):
"""Return a string representing the table's CREATE"""
cursor = conn.execute("SELECT sql FROM sqlite_master WHERE name=?;", [name])
sql = cursor.fetchone()[0]
cursor.close()
return sql
# the database connection
with sqlite3.connect('databases/panamapapers.sqlite3') as conn:
print("Opened database successfully")
# all tables
cursor = conn.execute("SELECT name FROM sqlite_master WHERE type='table';")
table_names = []
for row in cursor:
table_names.append(row)
for row in table_names:
transform = ''.join(row)
exe = "SELECT * FROM {};"
cursor = conn.execute(exe.format(transform))
names = list(map(lambda x: x[0], cursor.description))
print("\nNom de la table: " + transform + "\n")
print("A complete table scheme : ")
print(sqlite_table_schema(conn, transform), "\n")
print(" Et voici chaque colonnes:")
for columns in names:
print(" - " + str(columns))
print("Operation done successfully")Opened database successfully
Nom de la table: source
A complete table scheme :
CREATE TABLE source (
id INTEGER PRIMARY KEY,
source TEXT
)
Et voici chaque colonnes:
- id
- source
Nom de la table: status
A complete table scheme :
CREATE TABLE status (
status TEXT,
id INTEGER PRIMARY KEY
)
Et voici chaque colonnes:
- status
- id
Nom de la table: country
A complete table scheme :
CREATE TABLE country (
code TEXT,
country TEXT,
id INTEGER PRIMARY KEY
)
Et voici chaque colonnes:
- code
- country
- id
Nom de la table: address
A complete table scheme :
CREATE TABLE address (
address TEXT,
countries TEXT,
country_codes TEXT,
id_address BIGINT PRIMARY KEY,
source_id INTEGER
,FOREIGN KEY (source_id) REFERENCES source(id)
)
Et voici chaque colonnes:
- address
- countries
- country_codes
- id_address
- source_id
Nom de la table: intermediary
A complete table scheme :
CREATE TABLE intermediary (
id INTEGER
PRIMARY KEY
,name TEXT,
source_id INTEGER,
note TEXT,
/* url TEXT, */
id_address BIGINT,
status_id INTEGER
, url TEXT,FOREIGN KEY (id_address) REFERENCES address(id_address)
,FOREIGN KEY (source_id) REFERENCES source(id)
,FOREIGN KEY (status_id) REFERENCES status(id)
)
Et voici chaque colonnes:
- id
- name
- source_id
- note
- id_address
- status_id
- url
Nom de la table: entity
A complete table scheme :
CREATE TABLE entity (
id INTEGER PRIMARY KEY,
name TEXT,
jurisdiction TEXT,
jurisdiction_description TEXT,
incorporation_date DATE,
status TEXT,
service_provider TEXT,
source TEXT,
note TEXT,
id_address BIGINT,
end_date DATE
, url TEXT, lifetime INTEGER,FOREIGN KEY (id_address) REFERENCES address(id_address)
)
Et voici chaque colonnes:
- id
- name
- jurisdiction
- jurisdiction_description
- incorporation_date
- status
- service_provider
- source
- note
- id_address
- end_date
- url
- lifetime
Nom de la table: officer
A complete table scheme :
CREATE TABLE officer (
id INTEGER
PRIMARY KEY
,name TEXT,
source_id INTEGER,
note TEXT,
country_id INTEGER
,FOREIGN KEY (country_id) REFERENCES country(id)
,FOREIGN KEY (source_id) REFERENCES source(id)
)
Et voici chaque colonnes:
- id
- name
- source_id
- note
- country_id
Nom de la table: assoc_officer_entity
A complete table scheme :
CREATE TABLE assoc_officer_entity (
officer INTEGER,
assoc_type TEXT,
entity INTEGER,
source_id INTEGER,
start_date DATE,
end_date DATE
,FOREIGN KEY (officer) REFERENCES officer(id)
,FOREIGN KEY (entity) REFERENCES entity(id)
,FOREIGN KEY (source_id) REFERENCES source(id)
)
Et voici chaque colonnes:
- officer
- assoc_type
- entity
- source_id
- start_date
- end_date
Nom de la table: assoc_inter_entity
A complete table scheme :
CREATE TABLE assoc_inter_entity (
inter INTEGER ,
entity INTEGER,
source_id INTEGER,
FOREIGN KEY (inter) REFERENCES intermediary(id),
FOREIGN KEY (entity) REFERENCES entity(id),
FOREIGN KEY (source_id) REFERENCES source(id)
)
Et voici chaque colonnes:
- inter
- entity
- source_id
Nom de la table: assoc_officers
A complete table scheme :
CREATE TABLE assoc_officers (
officer1 INTEGER ,
assoc_type TEXT,
officer2 INTEGER ,
start_date DATE,
end_date DATE,
FOREIGN KEY (officer1) REFERENCES officer(id),
FOREIGN KEY (officer2) REFERENCES officer(id)
)
Et voici chaque colonnes:
- officer1
- assoc_type
- officer2
- start_date
- end_date
Nom de la table: assoc_intermediaries
A complete table scheme :
CREATE TABLE assoc_intermediaries (
interm1 INTEGER ,
assoc_type TEXT,
interm2 INTEGER ,
start_date DATE,
end_date DATE,
FOREIGN KEY (interm1) REFERENCES intermediary(id),
FOREIGN KEY (interm2) REFERENCES intermediary(id)
)
Et voici chaque colonnes:
- interm1
- assoc_type
- interm2
- start_date
- end_date
Nom de la table: assoc_entities
A complete table scheme :
CREATE TABLE assoc_entities (
entity1 INTEGER ,
assoc_type TEXT,
entity2 INTEGER ,
start_date DATE,
end_date DATE,
FOREIGN KEY (entity1) REFERENCES entity(id),
FOREIGN KEY (entity2) REFERENCES entity(id)
)
Et voici chaque colonnes:
- entity1
- assoc_type
- entity2
- start_date
- end_date
Nom de la table: assoc_inter_offi
A complete table scheme :
CREATE TABLE assoc_inter_offi (
inter INTEGER ,
assoc_type TEXT,
officer INTEGER,
start_date DATE,
end_date DATE,
FOREIGN KEY (inter) REFERENCES intermediary(id),
FOREIGN KEY (officer) REFERENCES officer(id)
)
Et voici chaque colonnes:
- inter
- assoc_type
- officer
- start_date
- end_date
Nom de la table: assoc_officer_interm
A complete table scheme :
CREATE TABLE assoc_officer_interm (
officer INTEGER ,
assoc_type TEXT,
interm INTEGER,
start_date DATE,
end_date DATE,
FOREIGN KEY (officer) REFERENCES officer(id),
FOREIGN KEY (interm) REFERENCES intermediary(id)
)
Et voici chaque colonnes:
- officer
- assoc_type
- interm
- start_date
- end_date
Operation done successfullyPour les Panama Papers, je vous donne les questions:
- Combien la base de données contient-elle de sociétés offshores différentes dont la source est « Panama Papers » ?
- Quel intermédiaire a créé le plus de sociétés offshores ? A-t-on son adresse et son pays ?
- Combien la base contient-elle de bénéficiaires avec un nom unique ? Quel est le bénéficiaire dont le nom revient le plus souvent ?
- Donner la liste des juridictions avec le nombre d’entreprises offshores enregistrées sur chaque territoire, triée par ordre décroissant.
- Regrouper les sociétés offshores par statut, et trier la liste par ordre décroissant.
- Trouver la liste des bénéficiaires dont le nom contient « BNP » et ajouter, pour chaque bénéficiaire, le nom des sociétés offshores.
- Trouver la liste des sociétés dont la juridiction est « France », « Monaco » ou « Réunion ».
- Trouver la liste des sociétés dont le pays de l’adresse et le pays de la juridiction sont différents.
- Trouver la liste des bénéficiaires qui ont des sociétés au même nom et enregistrée à la même date, trier la liste par odre décroissant.
- Donner la liste des intermédiaires qui ont aussi été bénéficiaires, en ajoutant leur nom de bénéficiaire et leur adresse.
Beaucoup de similarités entre le premier et le deuxième exercice, seulement les 2 dernières seront exposées:
- Donner le top 10 des bénéficiaires qui ont le plus d’identités différentes (similar name and address) et le nombre d’identités correspondant.
# the database connection
with sqlite3.connect('database_sqlite3/panamapapers.sqlite3') as conn:
print("Opened database successfully")
sentence = "Top {} officer with similar name and address (multiple identities): \n officer: {} , {} identities."
# all tables
i = 1
cursor = conn.execute("SELECT O.name, count(O.id) FROM officer as O, assoc_officers as AO WHERE O.id = AO.officer1 AND AO.assoc_type = 'similar name and address as' GROUP BY O.name ORDER BY COUNT(O.id) DESC LIMIT 10 ;")
for row in cursor:
print(sentence.format(i, row[0], row[1]))
i = i + 1Opened database successfully
Top 1 officer with similar name and address (multiple identities):
officer: NORTH ATLANTIC SERVICES LIMITED , 811 identities.
Top 2 officer with similar name and address (multiple identities):
officer: BROCK NOMINEES LIMITED , 575 identities.
Top 3 officer with similar name and address (multiple identities):
officer: TENBY NOMINEES LIMITED , 529 identities.
Top 4 officer with similar name and address (multiple identities):
officer: MOHUL NOMINEES LIMITED , 513 identities.
Top 5 officer with similar name and address (multiple identities):
officer: SCIVIAS TRUST MANAGEMENT LTD , 369 identities.
Top 6 officer with similar name and address (multiple identities):
officer: FORMIA LIMITED , 363 identities.
Top 7 officer with similar name and address (multiple identities):
officer: RICHMOND NOMINEES LIMITED , 355 identities.
Top 8 officer with similar name and address (multiple identities):
officer: ELCAN NOMINEES LIMITED , 312 identities.
Top 9 officer with similar name and address (multiple identities):
officer: DORCHESTER INTERNATIONAL INC. , 311 identities.
Top 10 officer with similar name and address (multiple identities):
officer: CAVERSHAM NOMINEES LIMITED , 300 identities.- Donner le top 10 des bénéficiaires qui ont le plus de parts toujours valides dans des entreprises offshores (dont la date de fin n’est pas encore passée).
with sqlite3.connect('database_sqlite3/panamapapers.sqlite3') as conn:
print("Opened database successfully")
sentence = "Number {} officer {}, Total offshore societies owned, still active : {}."
print("Officers with entities still 'Valid'")
cursor = conn.execute("SELECT O.name, count(O.id) FROM entity as E, officer as O, assoc_officer_entity as AOE WHERE O.id = AOE.officer and AOE.entity = E.id and E.status = 'Active' GROUP BY O.id ORDER BY COUNT (O.id) DESC LIMIT 10.")
i = 1
for row in cursor:
print(sentence.format(i, row[0], row[1]))
i = i + 1Opened database successfully
Officers with entities still 'Valid'
Number 1 officer MOSSFON SUBSCRIBERS LTD., Total offshore societies owned, still active : 2111.
Number 2 officer BOS NOMINEES (JERSEY) LIMITED, Total offshore societies owned, still active : 294.
Number 3 officer BOS SECRETARIES (JERSEY) LIMITED, Total offshore societies owned, still active : 284.
Number 4 officer MOSTALINA INVESTMENTS S.A, Total offshore societies owned, still active : 113.
Number 5 officer BROCK NOMINEES LIMITED, Total offshore societies owned, still active : 96.
Number 6 officer Dorchester International Inc, Total offshore societies owned, still active : 95.
Number 7 officer Cannon Nominees Limited, Total offshore societies owned, still active : 93.
Number 8 officer INTERCON LIMITED, Total offshore societies owned, still active : 87.
Number 9 officer MAYTREE OVERSEAS S.A., Total offshore societies owned, still active : 87.
Number 10 officer TENBY NOMINEES LIMITED, Total offshore societies owned, still active : 82.Réponses: https://github.com/alegarn/S4J4-THP2-Basic-SQL